Rehashing Orchestration vs Choreography
There is a lot of talk about Sagas and using choreography versus orchestration. I have referenced a few of them below. Having done this a few times with actual implementations, here are some of my thoughts.
Let’s start with a customary definition of what sagas are:
The saga design pattern is a way to manage data consistency across microservices in a distributed transaction scenario. -microsoft
Assuming you have done the pre-work on why microservices are the best approach for your organization, used Domain-Driven Design concepts to identify your subdomains or bounded contexts, and aligned your organization around them, you will end up with a bunch of services within one bounded context (like the colored ones at the start of this post). Now you are trying to ensure that your architecture is loosely coupled, failure-resistant, handles distributed transactions, scales with traffic, etc.
Side note: Microservices are about your organization setup, not just an architectural style.
You have picked one of the patterns to be your choice, given that it meets all of your needs. But before you do that, think about all the building and operational pieces as well.
- How well can you test them independently and integrated?
- You are building for failures with scale. How exactly would you handle failures at the business level?
- Can developers understand the whole flow when the application is being built? Hopefully, you are not waiting to do that integration testing at the very end.
- Can you quickly figure out what is going on in production when your customers complain that something is not working?
- What would supporting the system look like? Is it adding to the toil or reducing it?
Let’s look at slightly more detail for each approach. Our focus is on stateful services.
Choreography
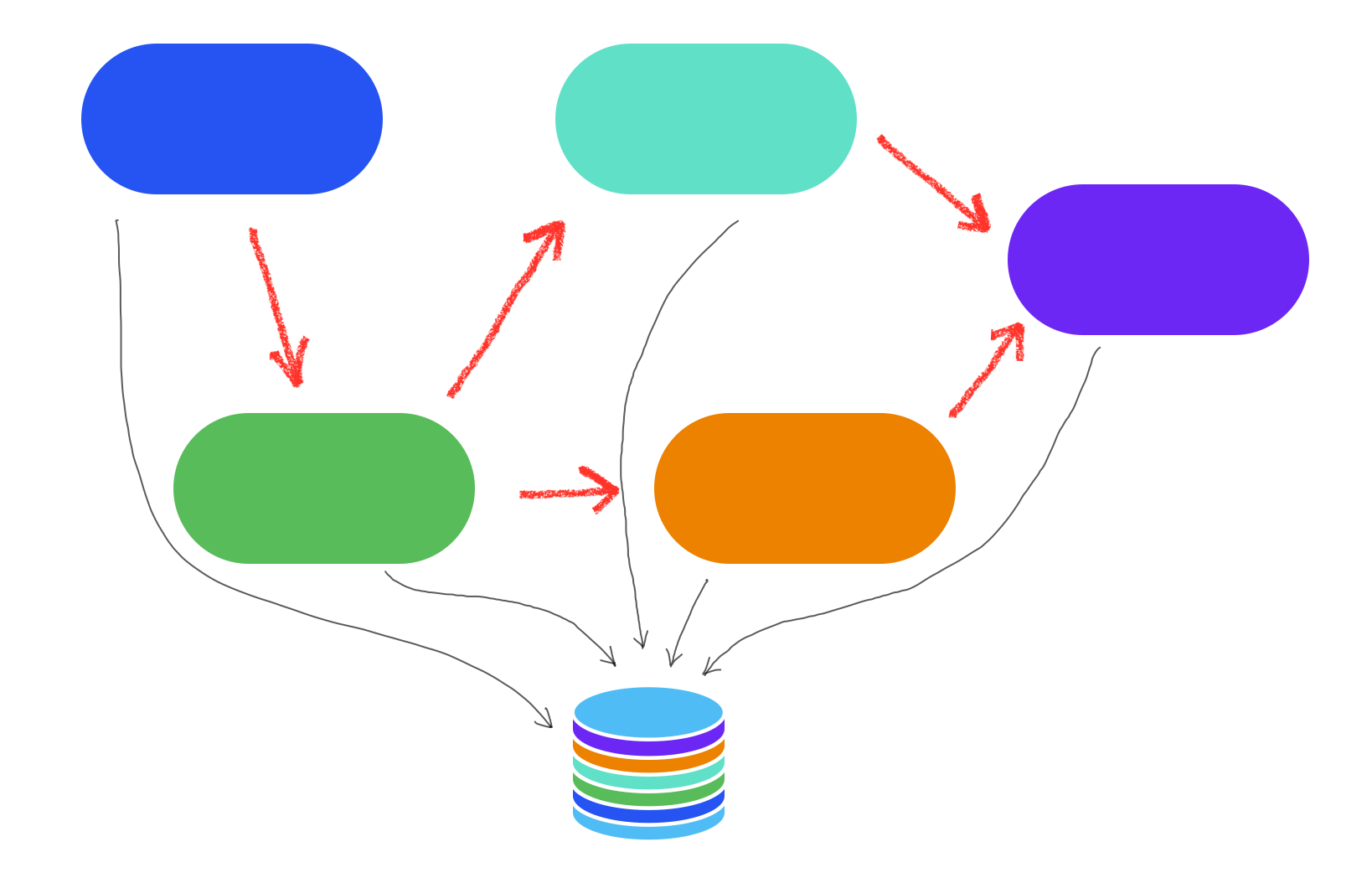
Many times, choreography starts out with a simple implementation using event-driven architecture but becomes increasingly complicated as the complexity grows. And well, that is the case with software - complexity ALWAYS increases with growth!
The biggest support I have heard for it is truly decoupled services. If done right, without any behavioral coupling, it allows for infinite and independent scalability. Moreover, as there is no coordination needed, there is no single point of failure.
The downside, which most teams find out during the build or after it’s in production for a while, is related to maintainability. Connecting all the services together, handling business failures, and integration testing them can become difficult. Who is organizationally responsible for the integration testing and maintaining the tests?
Another challenge is related to troubleshooting knowledge. As services are decoupled, you need a robust mechanism to stitch them together to have a holistic view of the flow. In situations where you might have to take manual action to fix an issue, such as injecting a compensating event, there should be additional support applications beyond the services themselves to make it easier for anyone to do it without specialized knowledge.
The maintainability challenges can be reduced by making the support software beyond the services themselves equally important. In the picture above, I have a database that receives all the events from these services. Let’s call it theflow stitcher. You can use something similar to stitch the flow after the fact and also build a UI or tooling around it to make it easier to view the overall flow, identify potential issues that might be blocking the flow, and then take corrective actions.
Orchestration
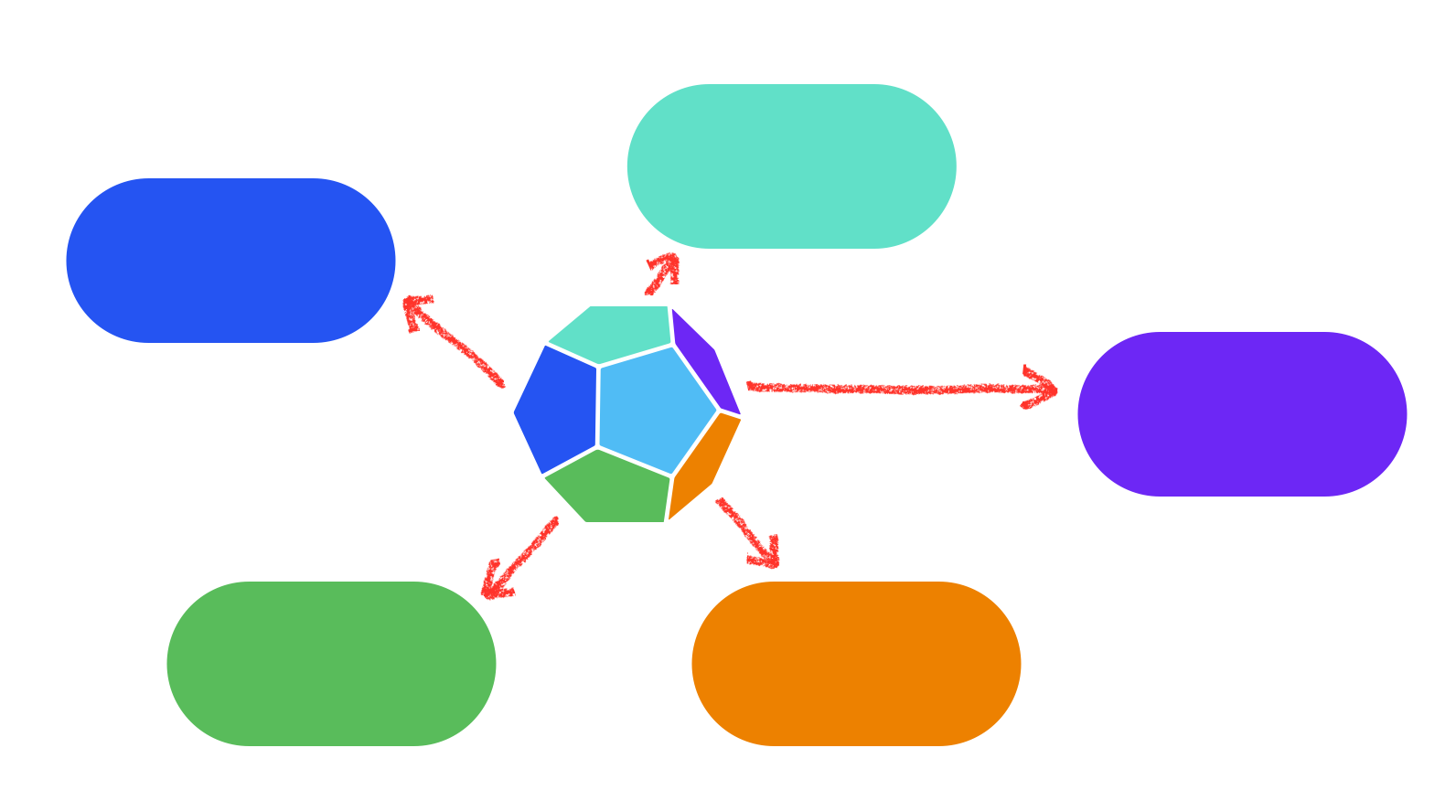
Orchestration, on the other hand, has a single coordinator across all services, making it easier to go to a single place to make sense of the flow, test, troubleshoot, and fix. Thus, maintainability becomes easier.
There are two downsides worth considering : coupling and single point of failure.
One school of thought argues that coupling increases between the services in orchestration, which is not the case with Choreography. However, I would argue that in choreography, there is still a domain coupling as each service needs to know about something another service publishes to make its business logic work. In orchestration, however, services don’t have to know anything about one another; it’s the coordinator who knows what makes sense to stitch together, potenitally reducing coupling.
Secondly, there is the issue of single point of failure and scaling. Introducing a new component does become a potential point of failure. However, this can be mitigated by ensuring that the orchestration engine itself is built on a strong foundation and sound architecture that can scale. If the underlying architecture of the workflow platform is built with patterns like event sourcing and is scalable in the cloud, then it can scale very well. The bigger your orchestration flow, the larger the impact of the single point of failure. It is advisable not to have a single flow for the entire company. Breaking the flows down and keeping them within the bounded context will not only reduce the single point of failure but also help with scaling different portions of your organization, both in terms of teams and architecture.
Parting thoughts
Like many answers to architectural questions, the better choice for your organization depends on the context.
- Match your choice to the stage of your organization. Organizations at different stages—starting, scaling, tackling complexity—will have different solutions.
- Use orchestration within the subdomain or bounded context and choreography across them. It’s not one versus the other. You always have the choice to mix both options.
- Reduce the toil by building for maintainability and developer experience from the beginning. This will pay off in the long run, so match it to the stage of your organization.
References
If you are building Microservcies, you need to understand what a bounded context is
Untangling Microservices
Saga distributed transaction pattern